Daily, billions of texts, emails, and online commentary rush through digital channels. This plethora of data-filled text-to-machine delivers a wide array of individual benefits to modern computer systems. Today, with basic natural language processing, computers can decode human languages with a relatively high hit rate. A systematic Data Science Online Course introduced novices to learn the most fundamental processes of creating paper trails of information. For example, e-commerce systems will read online comments on products and immediately sense bad comments.
Huge banks use such language systems to automate the analysis of news about the stock markets and forecast stock price movements automatically. Shipping firms use automation to read customs paperwork and sort delivery boxes by city. By sorting messy human text into neat lists, language models guide major business choices globally. Support teams can route customer help tickets to the correct desk in seconds. This approach stops slow manual sorting and speeds up daily work routines.

NLP Pipelines for Large-Scale Text Processing
Large text projects need a strict, step-by-step pipeline to prepare raw inputs for computer models. Raw text cannot go directly into math formulas without undergoing specific cleaning steps.
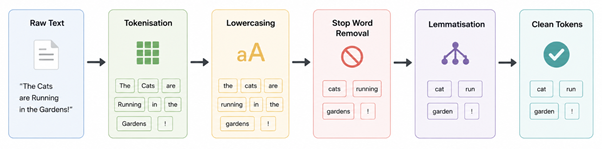
The Text Processing Workflow:
Core Pipeline Stages
- Tokenisation: Breaking up lengthy text paragraphs into smaller individual words or small chunks.
- Normalisation: making all words lowercase so that duplicates always match.
- Noise Removal: removing the excess HTML codes, odd symbols and punctuation.
- Stop Word Filtering: Remove all common words such as “is” or “the” that do not provide any meaningful information.
- Lemmatisation: normalise words to their stem word to establish a common structure.
| Pipeline Step | Input Text | Output Result |
| Tokenisation | “Running fast.” | “Running” , “fast” |
| Normalisation | “DATA Science” | “data” , “science” |
| Stop Word Filtering | “The clear sky” | “clear” , “sky” |
| Lemmatisation | “Studying histories” | “study” , “history” |
Live production systems use basic tools like SpaCy or NLTK to clean millions of files fast. These software libraries run automated cleaning tasks across many server computers at the same time.
Feature Extraction in Text Classification Models
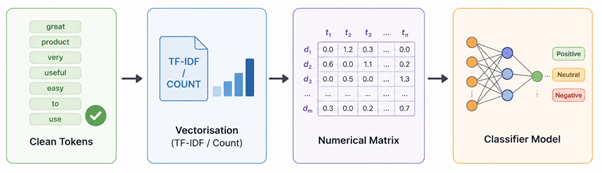
Computer models need numbers instead of raw words to run their internal math calculations. Feature extraction turns clean words into structured number grids to train simple text classifiers.
Common Vectorisation Methods:
- Bag of Words: Counts exact word frequency in a document. Completely disregarding the order of words.
- TF-IDF: Weighs words according to their worth in the document, devaluates words seen everywhere.
- N-grams: Groups nearby words into pairs or triplets to keep local phrase context.
A good Data Science Certification Course teaches students how to set up these numerical tools correctly. For example, a spam filter checks the math odds of words like “invoice” or “free” appearing together. If the final TF-IDF score beats a set limit, the email goes straight to the trash folder.
Sentiment Analysis for Customer Intelligence Systems
Sentiment analysis sorts text blocks into positive, negative, or neutral emotional score groups. Businesses use these setups to watch public brand image on social sites automatically.
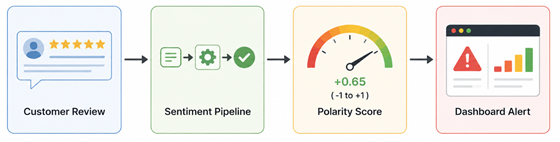
Real-World Sentiment Workflow:
1. The system grabs live text streams from public user feedback boards.
2. The text pipeline cleans inputs and picks out key descriptive words.
3. Classifier models score the text between minus one and one.
4. Low scores trigger fast alerts for customer help teams to fix the issue.
Engineers build these systems using Python tools like Scikit-Learn or basic text pattern modules. This setup lets companies track changes in public customer happiness hour by hour.
Named Entity Recognition in Unstructured Data
Named Entity Recognition finds and tags specific real-world nouns inside basic text blocks. The system scans files to pull out names, places, money values, and dates automatically.
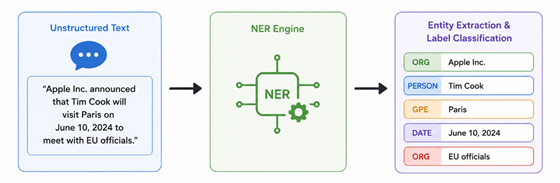
Extracted Entity Categories:
- Personnel: Full names of workers, clients, managers, or public leaders.
- Geography: Particular towns, states, office spots, or precise shipping locations.
- Organisations: Names of schools, companies, government agencies or groups.
- Quantities: This refers to things that are exact cash costs, percentage numbers, or just physically expressed quantities.
Industrial Application Example:
A law office scans thousands of old court files using an automated entity tool. The system extracts business names and contract end dates into an easy tracking sheet. This step saves junior staff from spending thousands of hours reading manual papers. Aspiring learners who want to build these tools often join a Data Science Course in Delhi to study.
Embeddings and Transformer Models in NLP
Modern language tools rely on deep learning nets to grasp complex meaning links between words. Old vector methods often fail to spot changing meanings in long text stories.
Vector Embeddings vs. Traditional Formats
- Dense Vectors: Dense vector embeddings visualise words in hundreds of spatial math dimensions.
- Context Awareness: The word “bank” gets different math scores depending upon words that are close in context.
- Semantic Similarity: Words with similar values are formed in the same section of the math chart.
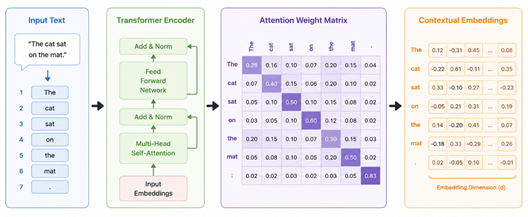
The Power of Transformers:
The attention math is at the heart of a transformer. Its built-in ability to understand how much each word influences all others replaces the linear reading of text, one word at a time. Platforms like Hugging Face provide ready-to-use transformer files, allowing developers to utilise frozen models. Results include intelligent search engines that understand intent.
NLP Challenges in Multilingual Data Processing
Running text models globally introduces various languages, different scripts, and grammar rules. Systems have to navigate special challenges when fronting a non-English information stream.
| Challenge Type | Technical Impact | Engineering Solution |
| Character Encodings | Breaks raw text files | Use universal UTF-8 text standards |
| Lack of Text Spaces | Ruins basic word splitting | Set up smart sub-word splitting tools |
| Scarce Training Data | Low sorting accuracy | Use cross-language model sharing tricks |
Global transformer models map distinct languages into one shared mathematical vector space. This allows a model trained on English text to sort Spanish files correctly without translating them first.
Conclusion
A stable text pipeline is created by connecting various data science components into a seamless system. Engineers should test data speed, computer memory constraints, and sorting precision while writing code. Selecting optimal tools for word tokenisation, creating embedding, and entity extraction resolves speed degradation. Interfacing high-quality data streams with state-of-the-art transformers enables teams to generate large-scale text systems.
